Paul Agapow (Bayezian / Skipping Girl Bio)
An gentle introduction to agentic AI: where it came from, what it is, and how everyone lost their goddamn minds. Presented to the PSI Data Science group, March 2026. Intended as an introduction to and mental model for the subject, a whirlwind tour not a comprehensive overview. Hence, it’s clipped and terse, being the talking points of a presentation, absent the surrounding extemporisation and discussion. The slides can be found here: https://www.slideshare.net/slideshow/agentic-ai-from-neurons-to-autonomous-systems/286345339
Also available on Substack at https://agapow.substack.com/p/from-neurons-to-autonomous-systems
How We Got Here
In a way, this all started with our attempts to infer over sequences, arrays of inputs or tokens that have an order and relationship to each other. Text, proteins, DNA, images …
While neural networks were invented in the 60s and had a heyday in the 80s and 90s, and were theoretically capable of approximating any function since the 1980s, they were limited in complexity for many years. When this complexity barrier was broken by improved training (along with GPU compute and large datasets) in about 2012, deep learning had its Big Moment. Suddenly, neural nets could handle big, real, interesting problems. As regards sequences, while the original neural architecture treated all inputs as equally related to (or equally independent from) one another, new architectures tackled the issue of related or adjacent inputs. Convolutional networks solved vision problems by representing neighbouring pixels as neighbouring connected inputs; recurrent networks and LSTMs tackled sequences by autoregression, inferring one position in the sequence and then feeding the results into the inference for the following position. But this approach is difficult to parallelise and has limited complexity.
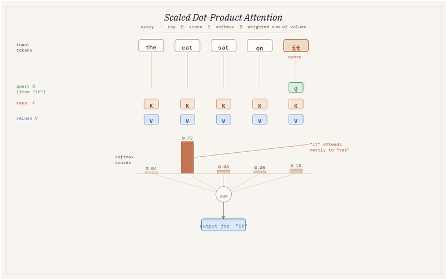
In 2015, attention mechanism solved this by letting the model selectively focus on any part of the input at any step, allowing inference for any token to use the context of other parts of the sequence, a sort of selective spotlight. The transformer architecture (Vaswani et al., 2017) took this idea, further discarding recurrence entirely, and inferring over any token for using only attention plus position encodings (so the model knows where every token is). This scaled predictably, could be trained in parallel, and generalised across domains.
In a sense, two lineages subsequently emerge from this:
- BERT and related transformer architectures, that consume a sequence as a whole and then are good at inferring and classifying terms within the text (e.g. keywords, names)
- GPT, which would move along a sequence, left to right, working on predicting the next token. This is a considerably simpler task and inherently generative: predicting the next token is the same as generating it. And this is how we get to LLMs …
Truly Weird Machines
Scale a GPT to hundreds of billions of parameters (weights), train it on all the data you can get, fine-tune its communication style based on human preferences (to sound polite, coherent, positive), and you get a Large Language Model or LLM. And these models turned out to have some surprising and unexpected abilities: it can hold conversations, generate code, do arithmetic, (apparently) reasoning. So people could talk to them, ask them for opinions, to make decisions, to do work …
Then everyone lost their goddamn mind.
Before showing where LLMs lead us, it’s important to understand some aspects of how they work. Several properties are structural and cannot be simply patched away:
- An LLM is stateless, has no memory between calls. Every conversation is a series of independent inferences; the illusion of continuity is maintained by passing your previous conversation to the LLM, like the amnesiac from Memento looking at notes to remember where they are and what they are doing.
- LLMs, like all models, are lossy compressions, generalisations of the data they ingest. “Hallucinations” are simply errors, compression artefacts where there is no information.
- Fine-tuned on human approval, these models have learned to communicate in an agreeable manner. Push back and they may cave: not because you’re right, but because you expressed displeasure and they have been trained to answer in a pleasing way.
- They are prompt-sensitive and non-deterministic. Small wording changes in requests can produce different outputs. The same question asked twice can yield different answers.
- A weird thing about the context provided to a model in that attention biases toward the start and end. Important information buried in the middle gets less weight.
- Finally, context size is naturally limited, and as this is approached (by providing a lot of information, by a long history of interactions), performance starts to degrade.
An agent is an LLM in a loop
An agent is an LLM that is orchestrated or directed towards autonomously completing a multi-step task: Observe → Think → Act → Repeat. A request is made of the agent; the agent computes (thinks); then acts or generates something; it examines the result of what it has done, and so on and so on …
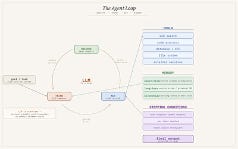
What makes this different from simple chatting with an LLM is:
- Orchestration: there is a framework controlling the agent, handing off work between agents; dictating tasks and stopping conditions
- Tools: the agent can actually do things: search, execute code, query databases, call APIs, read and write files.
- Memory (via context window, vector stores, structured logs) provides the statefulness the model itself lacks.
Agents could do anything, but what should they be used for? The sweet spot is:
- Tasks that are too long for a single prompt, where multi-step decomposition is required
- Tasks that have to be done on demand, dependent on live or data
- High-volume, exacting but repetitive work, where expert time is the bottleneck
- Jobs with a clear success criterion that can be evaluated automatically
In biopharma this could be trial protocol review, literature curation, data QC, regulatory drafting, patient screening. A six-week literature review delivered in hours with citations is a reasonable near-term expectation. Imagine a system that designs clinical trials:
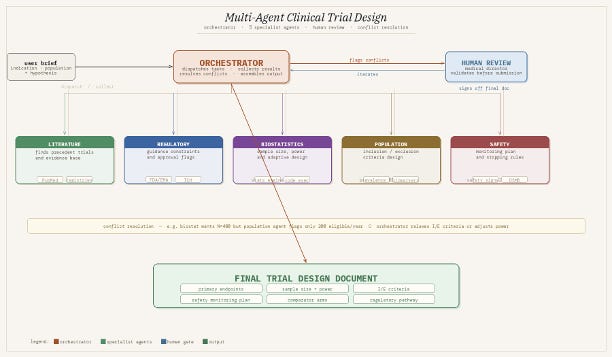
Best Practices
We are definitely still learning how to do this and LLM failure modes don’t disappear inside agents. Silent compounding failure is the characteristic risk, as with any automated system.
- Build evals (tests) before you build agents. Without scored, repeatable tests you are running blind.
- Start simple. Most ‘multi-agent’ problems can be solved with one agent and some tools. And not everything has to be an agent, but can be orchestration, simple code or logic gates. Add complexity only when you hit a real ceiling.
- Keep each agent’s task small and well-defined with a small number of steps. One agent, one job.
- Put humans in the loop for irreversible “failure is not an option” actions: sending, deleting, submitting, purchasing.
- Set hard limits on cost and steps. Unbounded agents find loops you didn’t anticipate.
- Log everything. Traces are your primary debugging tool.
- It’s a good idea, I think, to approach a lot of agent work as being a good way to get to your “shitty first draft”. Then a human can take over, or revise and hand back to the agents.
Vibe coding
If you can use agents to write documents, you can use them to write code. So people started doing that. Even at an early stage, the ability of LLMs was fairly impressive to generate or translate pieces of code. What’s changed is the use of agents to do a huge span of software development: generating & deploy whole projects, writing tests, writing documentation … there came the promise of literally knowing nothing about programming and being able to produce a fully working piece of software.
Then everyone lost their goddamn mind.
There are dangers there (some of the produced software is unmaintainable, contains grievous security holes, can’t easily be extended or modified because literally no one understands it). But there is also a bunch of interesting work to do with specification and test-driven development.
Interesting directions and advice
- There is so much going on that it’s impossible to keep up. You want to use these tools to get your work done, and not just endlessly tweak and configure LLMs all day. Perhaps you should stay one step behind the curve.
- Different LLMs have different strengths. It’s definitely worth looking around. The free levels are sometimes underpowered but lower paid tiers should be fine.
- For vibe coding look at Antigravity and ClaudeCode. Check out some of the work that Github is doing.
- MCP (Model Context Protocol) is an emerging standard for tool APIs
- LLMs carry a lot of useless (and possibly distracting) knowledge. Small models are an interesting new direction, with possibly more focused and predictable abilities.
- Read Andrej Karpathy who is an enthusiast but a balanced and reasoned one.
- Ignore the extremists & boosters who want you to go all in and spend all your time with the latest bleeding-edge tech.
OpenClaw: A Live Case Study
This has got so much air time, that I have to discuss it.
It used to be very complex to build agentic systems, with a wide span of unintegrated tools and libraries. This changed recently and unexpectedly. OpenClaw (formerly ClawdBot/MoltBot) is an open-source agent that combines tool access, persistent memory, code execution, and consumer messaging integration into a system that can run on your local machine, accept instructions via WhatsApp or Telegram, access and manage your mail, your calendars, the commandline …
So, of course, everyone lost their goddamn mind.
People started using it to run their lives, letting it post to social media, manage appointments … It hit 247,000 GitHub stars in months. It also illustrated every failure mode in this essay simultaneously: 500+ security vulnerabilities, 20% of marketplace plugins malicious, an agent deleted a user’s inbox. One maintainer warned it was too dangerous for anyone who couldn’t run a command line.
It’s incredibly interesting. But it’s definitely an early, early preview. The capabilities are real. The governance is not yet there. The distance between that chaos and a properly evaluated, human-in-the-loop system is the practical challenge of the next few years.
Leave a Reply